

OpenAI released GPT‑5 today and it is now state-of-the-art (SOTA) across key coding benchmarks, scoring 74.9% on SWE-bench Verified and 88% on Aider polyglot.
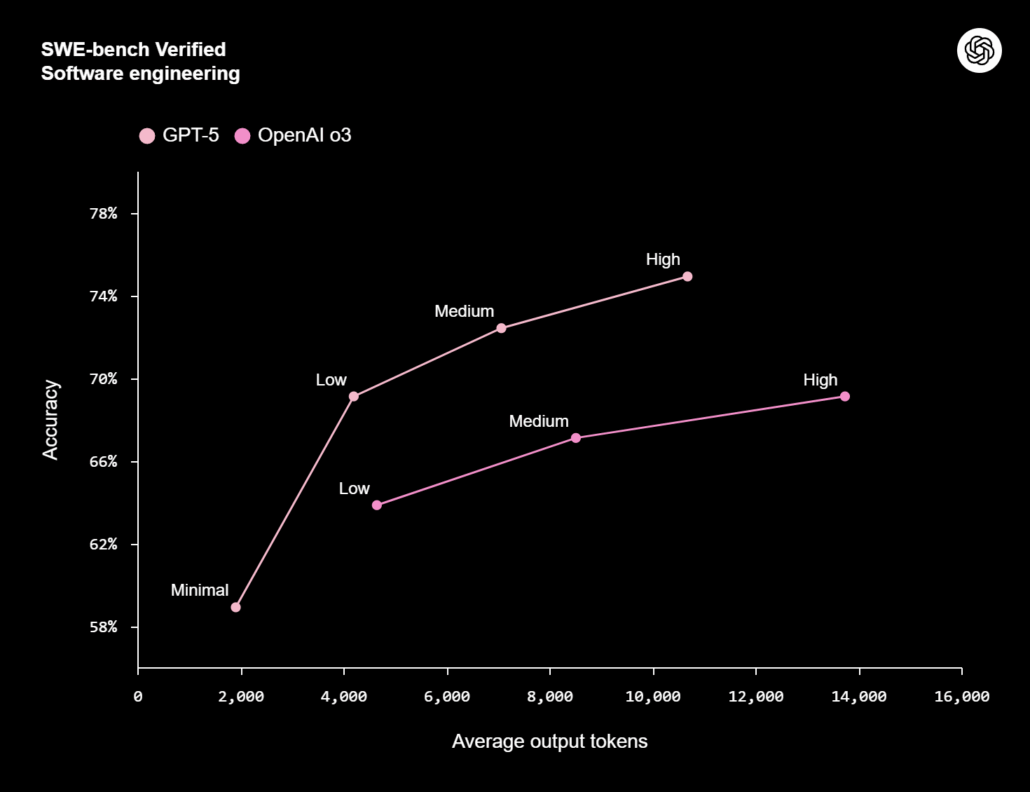
SWE-bench Verified: (Tests AI models on real-world GitHub issues, evaluating their ability to generate accurate code patches)
GPT-5 with Thinking (High) scored highest with 74.9%, followed closely by Claude Opus 4.1 at 74.5%. For comparison, OpenAI o3 High scored at 69.1%

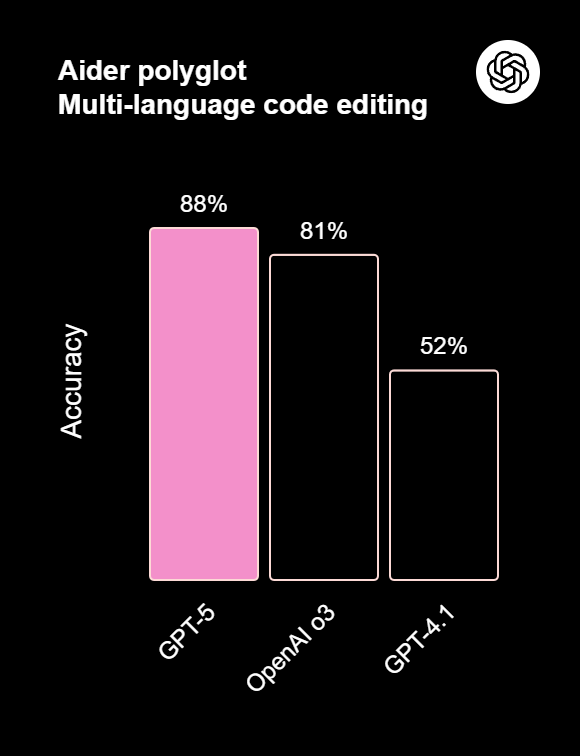
Aider Polyglot: (Evaluates code editing across multiple programming languages (e.g., Java, Rust, Python):
GPT-5 dominates with 88%, a substantial lead over competitors. Grok 4 comes in next at 79.6%. For comparison, OpenAI o3 came in at 81%.

This new era of AI Assisted coding LLMs just keeps getting better and better each day!