For the past couple of months, I have been co-developing a Moon Landing simulation game using several different open source LLM models running “locally” on my Alienware Aurora 11 GeForce RTX 3080 10GB VRAM video Card. Running LLMs locally using my RTX 3080 is completely free compared to using cloud based LLMs. I have been using a free program called Ollama for my local LLM coding tests.

In my coding tests, I was getting between 12 to 16 tokens per second depending on which Open Source LLM database I loaded locally into the RTX 3080 10GB of VRAM on my Alienware development PC.
I tested building a Lunar Lander simulation game using the open source qwen2.5-coder:7b and the open source deepseek-coder:6.7b LLM models to see how the coding quality results compared to the Lunar Lander game that we previously built (without using AI assistance) in our Programming Games with Visual C# 2017 textbook.
I picked these specific open-source coding models because they have been optimized for coding, and they fit into the 10GB of VRAM of my GeForce RTX 3080 video card.
Building the Lunar Lander simulation game using deepseek-coder:6.7b came in at 15.68 at tokens per second:
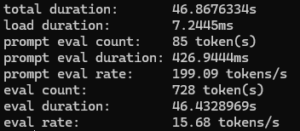
Building the Lunar Lander simulation game using qwen2.5-coder:7b came in at 12.36 tokens per second:

I also tested several other local LLM models that would also fit into my RTX 3080 10GB of VRAM for general LLM chat performance.
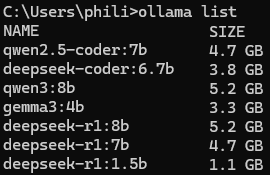
DeepSeek-Coder 6.7B was the best all-around local coding model for my GeForce RTX 3080 10GB video card. It handled multiple programming languages and had strong instruction-following and problem-solving capabilities.
Meta’s Code Llama 7B is also fine-tuned for code It also had strong results on both HumanEval and MBPP tests. It was pretty good for code completions, bug-fixes, and code explanations. It uses slightly heavier RAM use than DeepSeek-Coder model and is a little slower.
Based on my testing, I am pretty happy with the performance of both of these two local LLMs for AI assisted coding. They allowed me to code a Visual C# Lunar Lander game project without having to pay for the more expensive tokens and limitations of cloud based LLMs.
I only wish that I had more VRAM to test larger LLMs locally. Perhaps someday I might have to upgrade my AI Assisted Local LLM Game Development system to a larger GPU with more VRAM (e.g. RTX x090) or get a new AI laptop with an AMD AI Ryzen Max Pro 395 with 128GB of integrated RAM.
I’ll continue my testing throughout the summer and let you know my final conclusions about using local LLMs for coding after I have completed all my comparison tests.

