Over the past 6 months, I have continued to test locally hosted open-source multimodal agentic models which could run comfortably on my Nvidia RTX 3080 with 10GB. Back in the August, I added GLM 4.5 to my testbench as it was surpassing or matching DeepSeek V3, Qwen 2.5 Coder, and Llama 3.1 in benchmarks. At the time, I was busy testing OpenAI GPT OSS so I didn’t get a chance to write a blog post about my GLM 4.5 testing.
Z.ai (Zhipu AI) recently launched GLM 4.6V Flash on LM Studio which is a 9B vision-language model optimized for local deployment and low-latency applications. It supports a context length of 128k tokens and achieves strong performance in visual understanding among models of similar scale. The model introduces native multimodal function calling, enabling vision-driven tool use where images, screenshots, and document pages can be passed directly as tool inputs without text conversion.
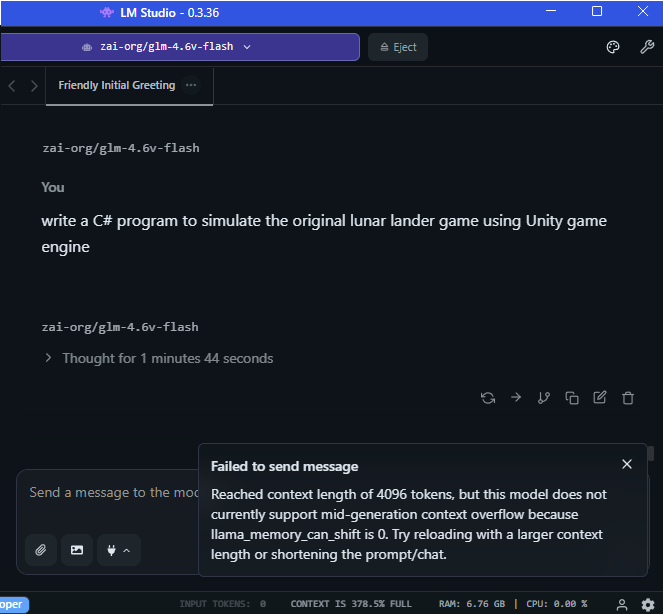
It needs a “minimum” of 8GB VRAM to run so I ran my standard Lunar Lander Simulation coding test using the default 4096 token context window. My initial coding test quickly reached the LM Studio default 4086 context window and errored out with a “Failed to send message” after 1 minute and 44 seconds:
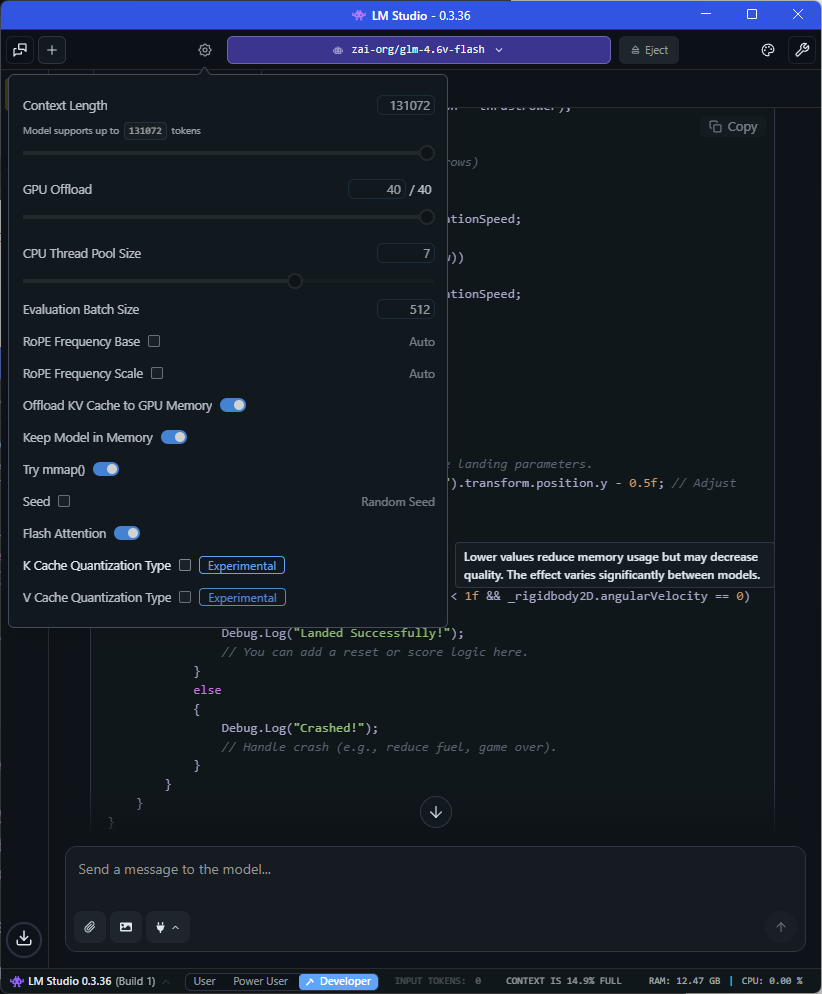
I then reloaded the model with a maximum token context window of 131072 with maximum layers offloaded to the GPU:
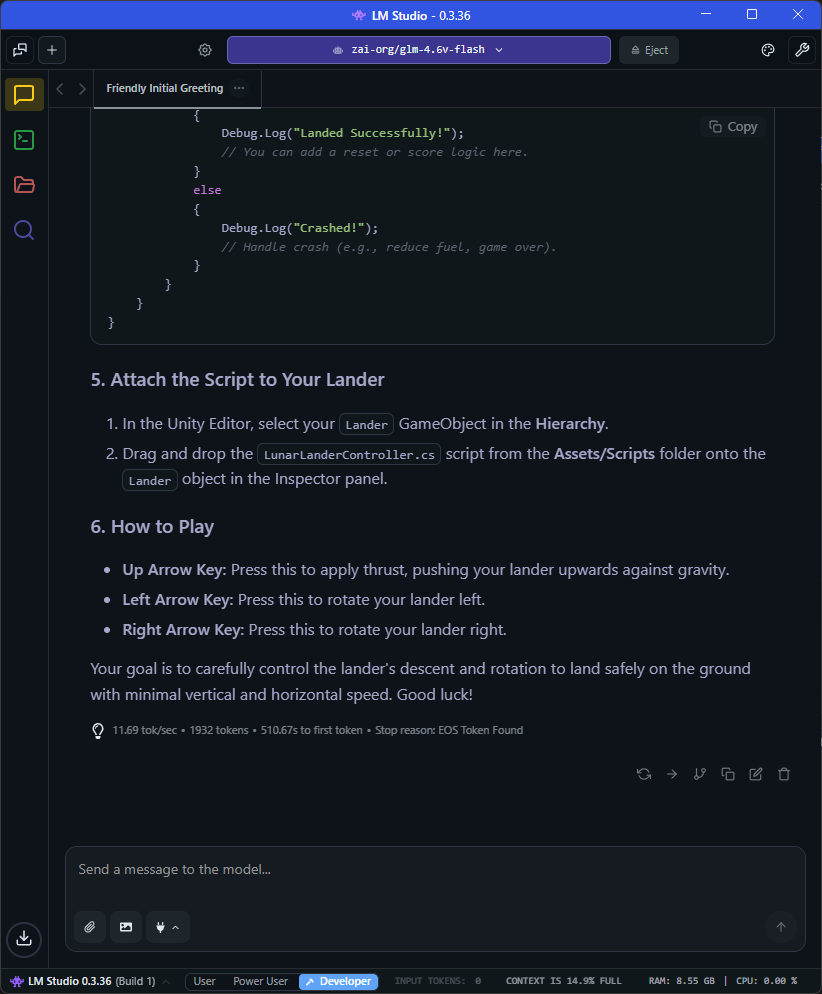
The Lunar Lander coding simulation coding test then ran without any problems at 11.69 tokens per second:
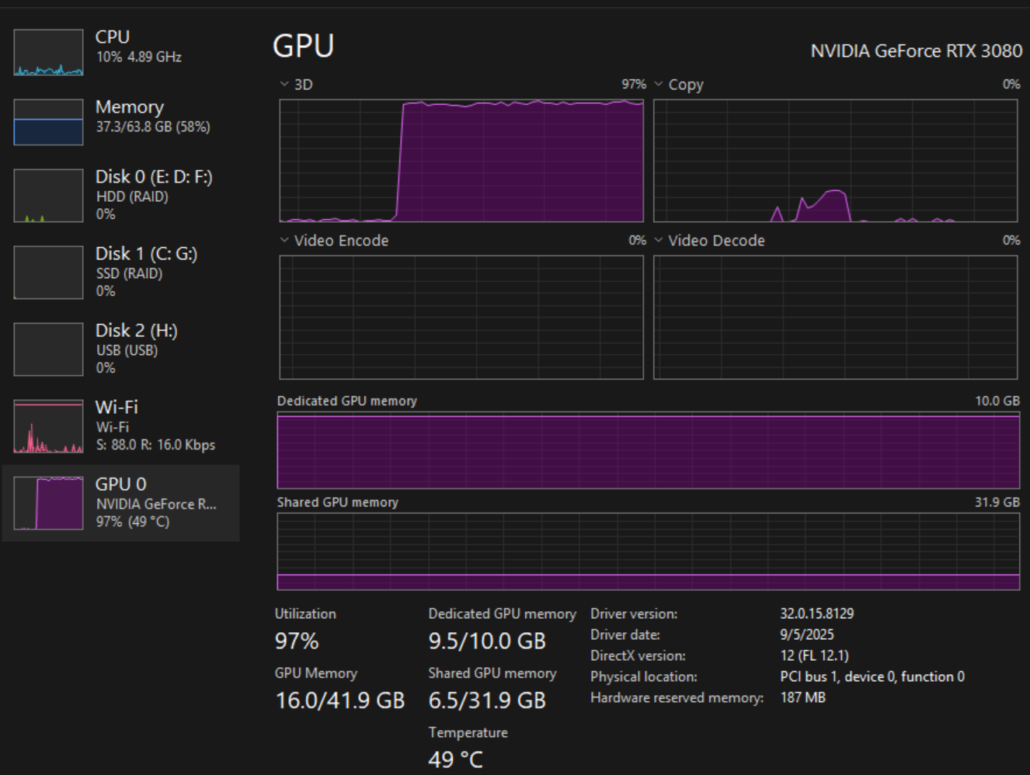
Below you can see the Task Manager Performance Chart for my NVIDIA GeForce RTX 3080;
GLM 4.6 scored 81% on GPQA, 93.9 on AIME 2025, and 69% on SWE-bench Verified. The Open Source LLM Models keep getting better and better at coding with each new release and the releases keep coming out faster and faster. Z.ai just released GLM 4.7 on December 22, 2025, and it quickly jumped to the top of the Open-Source Leaderboard. The new GLM 4.7 scored 85.7% on GPQA, 96.7 on AIME 2025, and 73.8% on SWE-bench Verified. Once the new 4.7 Flash model gets uploaded to LM Studio, I’ll test the new 4.7 model as well.
Wishing you and your family a Merry Christmas and a Happy New Year!