Using OpenAI GPT-OSS Open Weight Local LLM Model to Develop a Moon Landing Simulation Using C# on my Alienware Aurora R11 RTX-3080 10GB Video Card
OpenAI released their new Open Weights local LLM model today under the Apache License that you can download and run it locally on your own hardware without the need of a cloud subscription. The larger 120 billion parameter model will require a system with an 80GB GPU (who has that!?) or a MAC M3/M4 system with at least 128GB of Integrated/shared memory. The new AMD Ryzen AI 395 Max + 395 with 128GB can also run the 120B parameter model locally. You can definitely run the smaller 4-bit quantization 20 billion parameter model locally using a NVidia GeForce 3090, 40×0 or 50×0 video card with at least 16GB of VRAM. I personally downloaded the smaller 20B parameter model and got around 11 tokens per second using my RTX 3080 with 10GB using LM Studio. Some of the GPT-OSS 20b model had to be loaded into my local system ram on my Alienware A11 which made it run much slower.
On a system with 16GB VRAM or 128GB of Integrated memory, the free GPT-OSS LLM performs pretty well on the Codeforces Competiton code benchmark tests against OpenAI’s other subscription-based cloud LLMs:
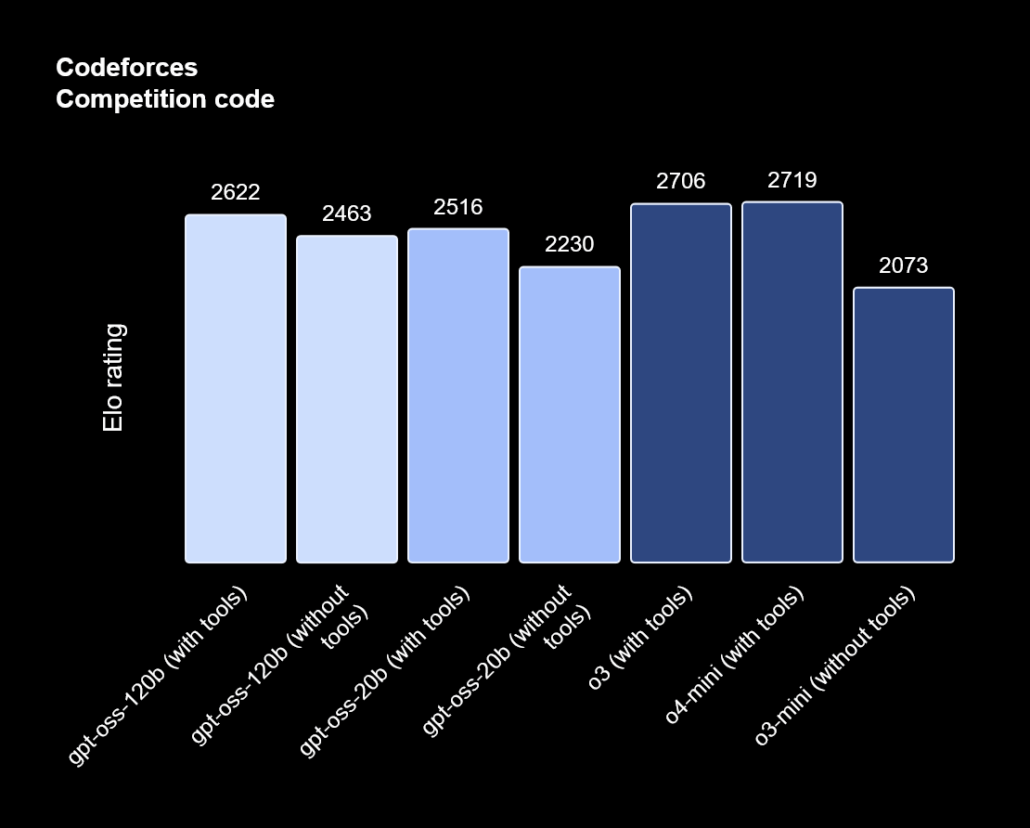
Source: Codeforces Benchmark from OpenAI
Since I only have 10 GB of VRAM on my RTX-3080, I tested GPT-OSS-20b with LM Studio and offloaded some of the model into my 64GB of system memory. I first tested it with a simple Hello World C++ application, and I got an average of 11 tokens per second dividing the model between high-speed Ge-Force VRAM and slow system RAM.
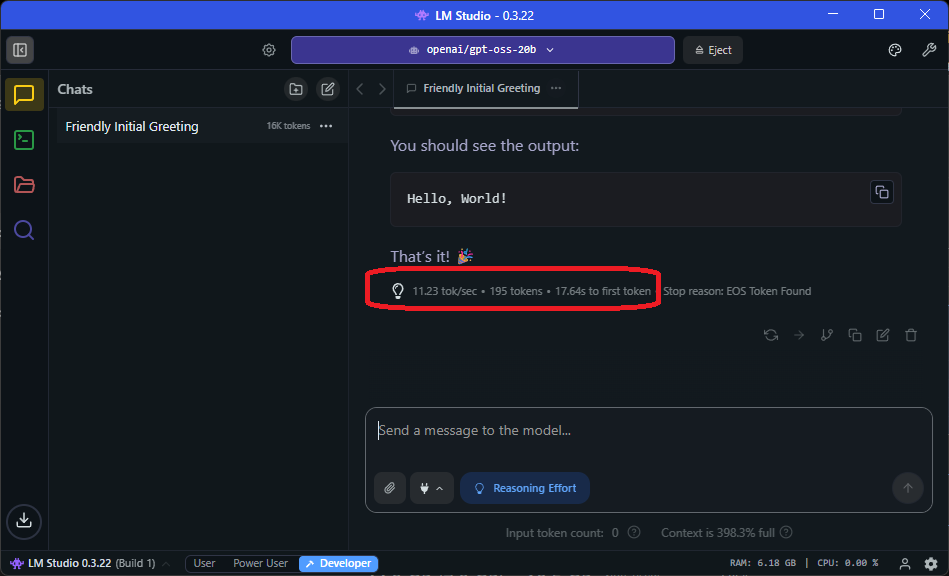
I then tested it by building a much larger C# Moon Landing simulation and it ran out of context memory, and it did not complete the coding task.
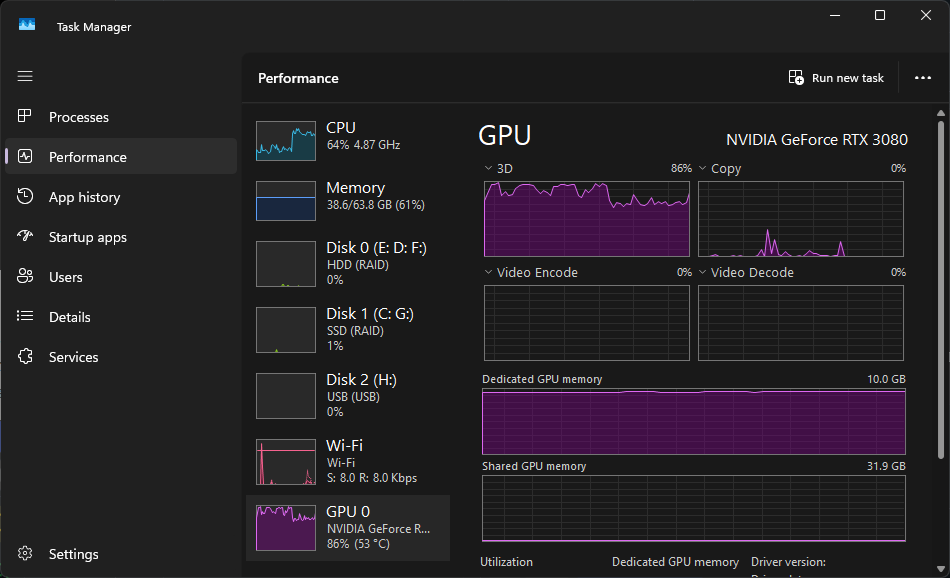
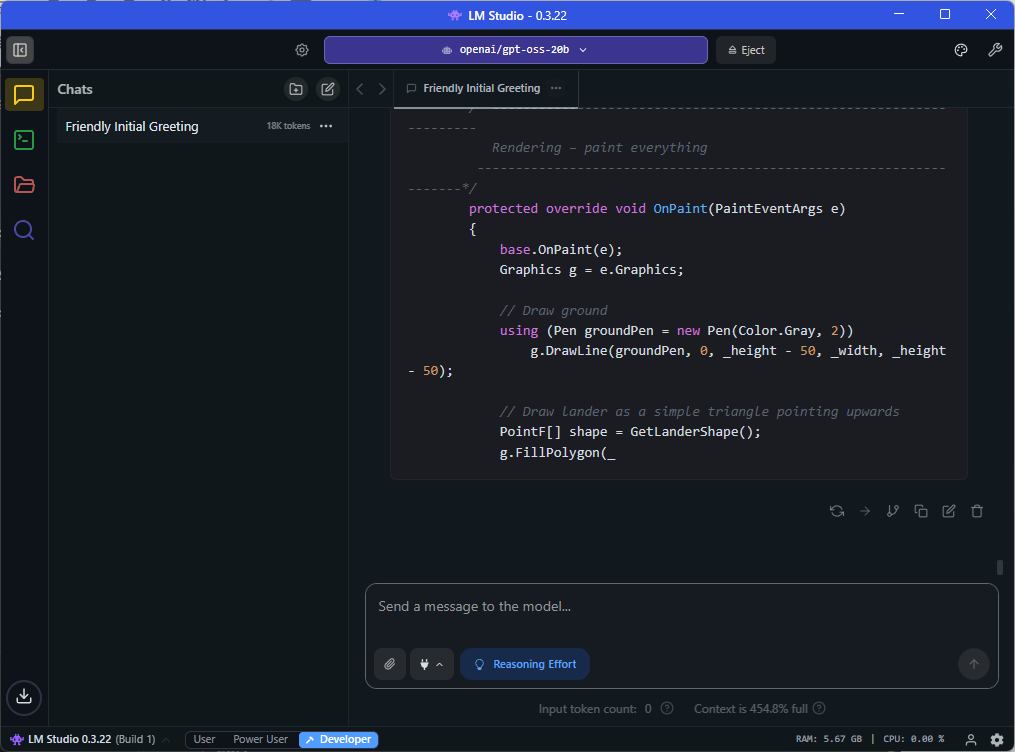
Update: I finally figured out how to enlarge my context window on LM Studio to 131072 and was able to successfully build the Lunat Lander game:
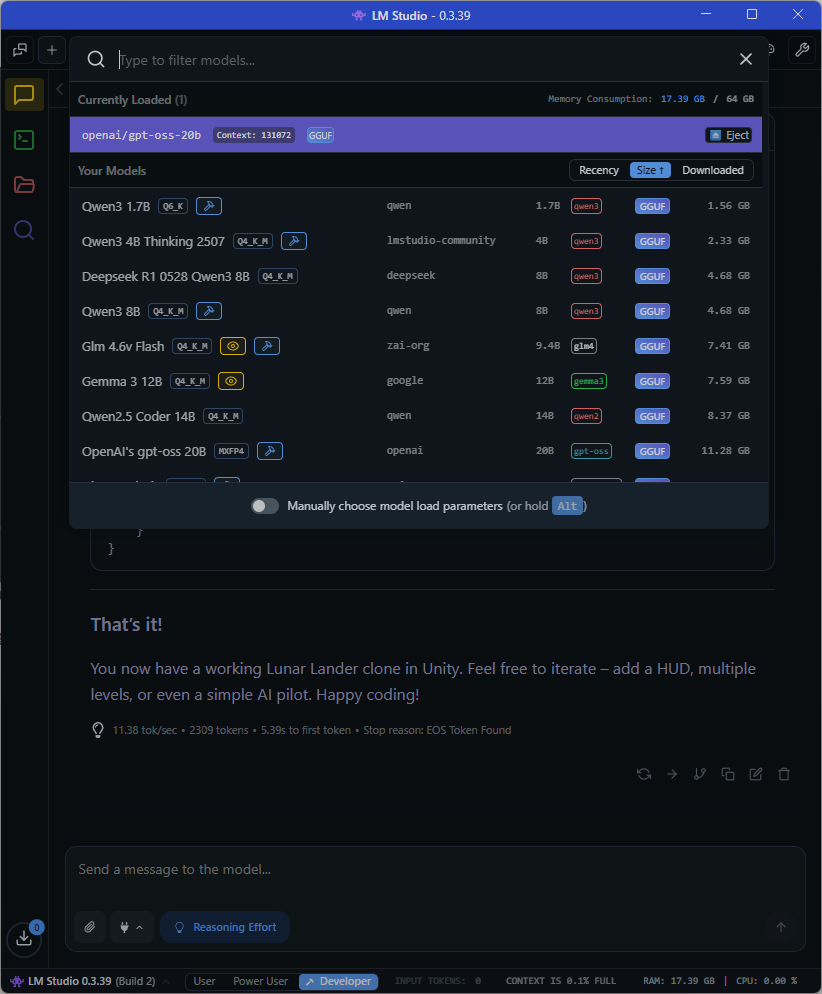
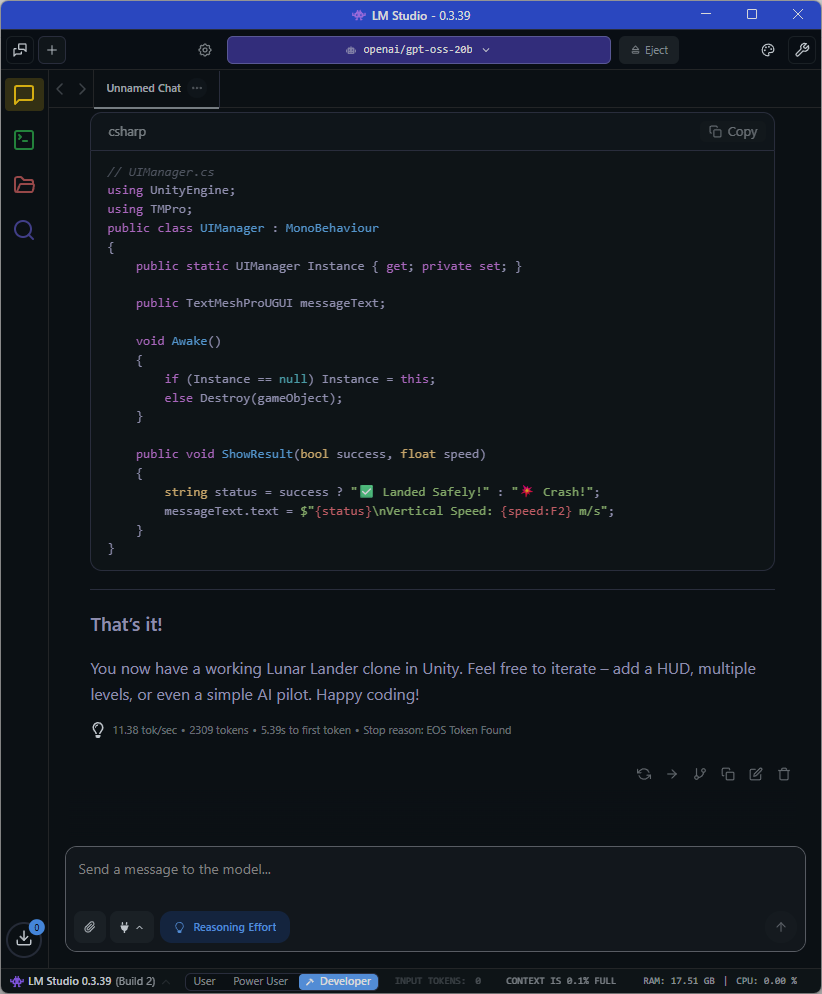
I definitely need to have at least 16 of VRAM, or better yet, 128GB of shared integrated memory in my development system to get faster local GPT-OSS LLM performance along with a bigger context window to complete this Moon Landing C# AI Assisted coding task.
Microsoft also announced today that you can also try it out in Foundry Local or AI Toolkit for VS Code (AITK) and start using it to build your Microsoft applications today using the GPT-OSS local LLM models. Let the free local GPT-OSS LLM Open Weights AI Assisted App & Game Development begin!