Using the GLM 4.7V Flash Local LLM Model by Z.ai to Develop a Moon Landing Simulation Using C# on my Alienware Aurora R11 RTX-3080 10GB Video Card
The GLM-4.7 Flash model, an Open Weight 30B-parameter Mixture of Agents (MoE) variant, released by Beijing Zhipu Huazhang Technology Co., Ltd on January 19, 2026, is positioned as a lightweight, efficient option for local deployment and agentic tasks like coding.
The Lunar Lander coding simulation coding test ran without any problems at 6.12 tokens per second using LM Studio:
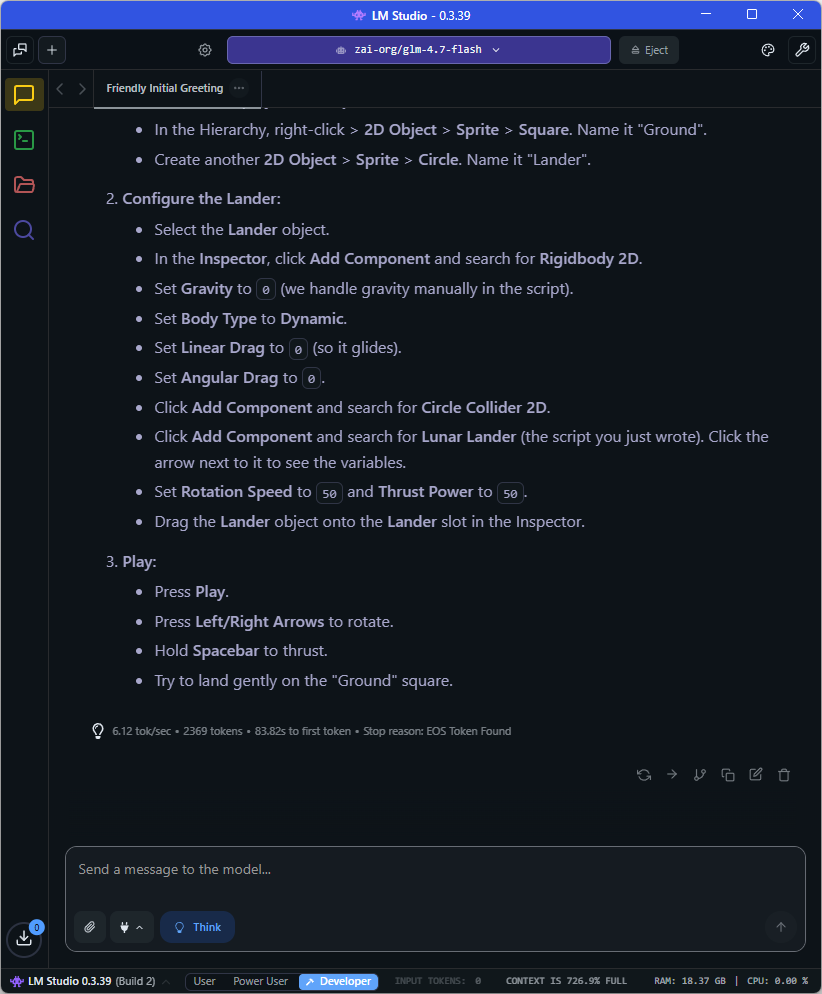
Below you can see the Task Manager Performance Chart for my NVIDIA GeForce RTX-3080 with 10GB VRAM;
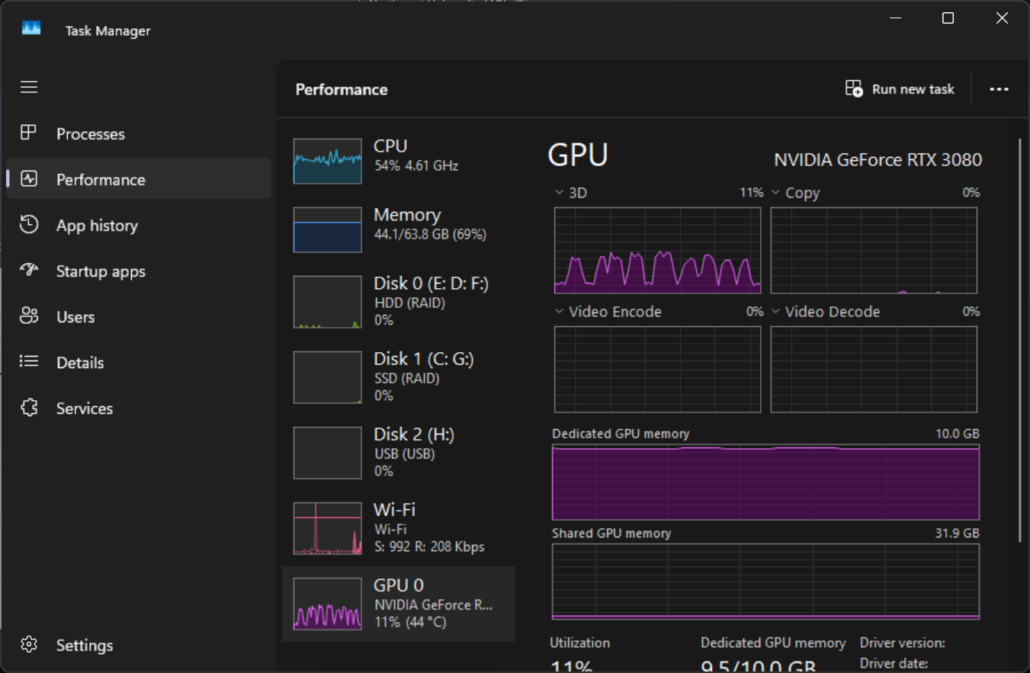
Based on available benchmark data, it achieved the following scores on the specified evaluations:
GPQA: 75.2%
AIME 25: 91.6%
SWE-bench Verified: 59.2%
These results position it as a strong performer in its size class, particularly for coding and reasoning, outperforming comparably sized models like Qwen3-30B on SWE-bench Verified while maintaining lower resource requirements. Note that benchmarks can vary slightly based on evaluation configurations, but these figures are consistent across official sources and reviews.