AI Co-Development Just Got a Lot Easier with the Release of Claude Opus 4.6 and Open AI GPT 5.3 Codex on February 5, 2026
In this article, I will compare two specific domains: coding an agentic application (e.g., autonomous AI agents that use tools, plan multi-step workflows, interact with environments like terminals/browsers, debug in loops, and handle real-world software engineering) and game development (e.g., designing game logic, implementing mechanics in engines like Pygame/Unity-style code, handling physics/AI/pathfinding, procedural generation, balancing systems, and iterating on prototypes).
On February 5, 2026 Anthropic released Claude Opus 4.6 which is their current flagship, optimized for the most demanding, long-horizon, and complex tasks. On the very same day, OpenAI released GPT-5.3 Codex (the dedicated agentic coding line). GPT-5.3 Codex is OpenAI’s current flagship for advanced coding and agentic workflows.
Key Specs Comparison:
Context Window
- Claude Sonnet 4.5: 200K tokens Claude Opus 4.6: 200K standard / 1M tokens (beta, with much higher reliability) GPT-5.3-Codex: Not explicitly stated in releases (likely 200K–512K range, consistent with GPT-5 family; strong on long-horizon without 1M claims yet)
- Pricing (API, per million tokens) Sonnet 4.5: $3 input / $15 output Opus 4.6: $5 input / $25 output (higher beyond 200K) GPT-5.3-Codex: Similar to prior GPT-5.x tiers (~$5–15 input / $15–75 output range; exact Codex rates match high-tier GPT access via app/CLI/API)
- Speed Sonnet 4.5: Fastest of the three for iteration Opus 4.6: Slower (deeper thinking/effort modes) GPT-5.3-Codex: ~25% faster than GPT-5.2-Codex; feels responsive for agent steering
- Reasoning/Agent Style All three are hybrid/agentic-tuned. Opus 4.6 has adaptive effort + best long-horizon sustain. GPT-5.3-Codex emphasizes steerable, interactive agents (you guide mid-task without context loss). Sonnet 4.5 balances speed + quality.
Performance on Agentic Coding / Building Agentic Applications
This category is extremely competitive right now — the February 5 releases were direct head-to-heads.
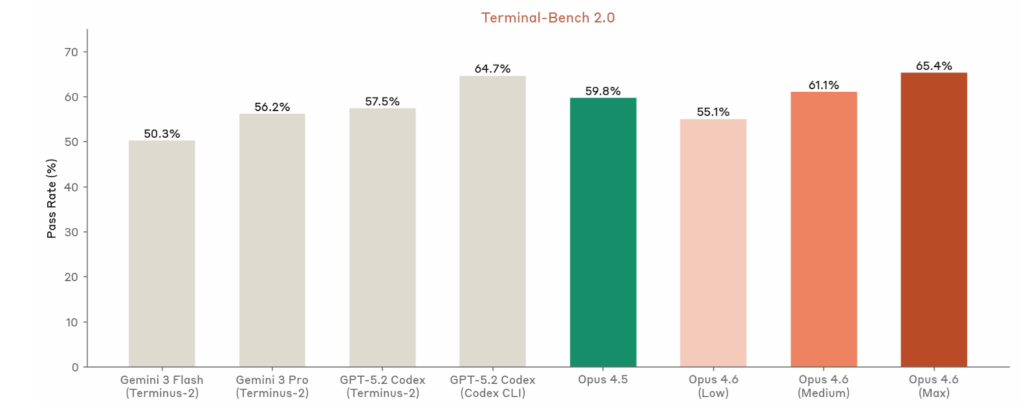
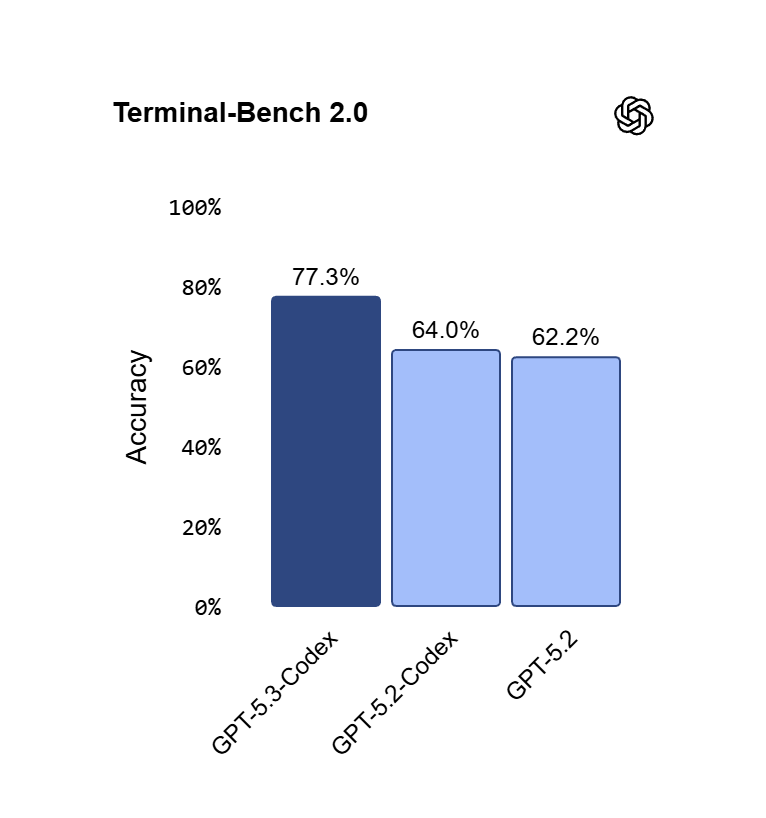
- Terminal-Bench 2.0 (terminal/tool-use agentic coding): GPT-5.3-Codex leads at ~77.3% (state-of-the-art claim); Opus 4.6 close behind (~65–72% range in prior reports, but Anthropic claims top on agent evals); Sonnet 4.5 lower (~51%).
- SWE-Bench Pro/Verified (real GitHub issues, multi-lang): GPT-5.3-Codex hits new highs on Pro variant (multi-lang, harder); Opus 4.6 edges on Verified for complex fixes (~80–81%); Sonnet 4.5 strong but trails slightly.
- OSWorld / Computer Use: GPT-5.3-Codex strong (~64–65%); Opus 4.6 leads in sustained GUI/terminal chains.
- Long-horizon Agents: Opus 4.6 excels at multi-hour autonomous runs, massive context, self-correction. GPT-5.3-Codex shines on interactive steering (like a live colleague) + tool/research chaining. Sonnet 4.5 great for volume/prototyping but needs more retries on extreme complexity.
- Real-world vibe: Developers report GPT-5.3-Codex feels “more Claude-like” than prior OpenAI models (better git, debugging, broad tasks). Opus 4.6 often wins on deep codebase navigation + fewer hallucinations. Many use both in parallel.
Below is Anthropic’s Terminal Bench 2.0 Rating of 65.4%
Below is OpenAI’s GPT-5.3 Codex Terminal Bench 2.0 Rating of 77.3%
For serious agentic apps (autonomous tools, computer-use agents, production reliability): It’s a toss-up between Opus 4.6 (best long sustain + 1M context) and GPT-5.3-Codex (interactive steering + benchmark edges). Sonnet 4.5 is excellent but not quite frontier here.
Performance on Game Development
Game dev favors creativity + systems integration + rapid iteration (mechanics, AI, procedural gen, balancing, physics sims).
- All three handle Pygame prototypes, Godot/Unity pseudocode, NPC AI, etc., very well.
- Sonnet 4.5: Best for fast prototypes/iterations — clean loops, quick balancing tweaks, simple pathfinding/behavior trees. Preferred for indie-speed work.
- Opus 4.6: Pulls ahead on complex, interconnected systems (e.g., economy + AI opponents + physics + UI + narrative). Better at coherent large-scale design → code chains, debugging edge cases in bigger codebases, creative-yet-coherent ideas.
- GPT-5.3-Codex: Strong contender — OpenAI highlights building “highly functional complex games and apps from scratch over days.” Excels at multi-step execution + research/tool use (e.g., pulling refs for mechanics). Feels more “productive” for iterative game workflows.
For most game prototypes/indie dev: Sonnet 4.5 (speed + cost) or GPT-5.3-Codex (if you want interactive guidance).
For ambitious/systems-heavy games (e.g., simulation layers, procedural worlds, long dev cycles): Opus 4.6 edges out slightly on cohesion + autonomy, but GPT-5.3-Codex is very close and often faster to iterate.
My Current Recommendation for “paid” Cloud AI Agent Development:
- Claude Sonnet 4.5 — Default choice for 80% of agentic coding + game dev: fast, cheap, reliable near-frontier.
- Claude Opus 4.6 — Pick for the hardest agentic/long-horizon work, massive context, or when you need max reliability/cohesion (especially complex games or production agents).
- GPT-5.3-Codex — Pick (or combine) if you value interactive steering, OpenAI ecosystem (Codex app/CLI/Copilot integration), or hit edges where OpenAI’s benchmarks shine. It’s neck-and-neck with Opus 4.6 right now — many developers test both on the same task.
I am testing all 3 models using OpenRouter as I test the Neostack AI Plugin for Unreal Game Development. The AI Assisted Video Game Development race is razor-close! Real preference often comes down to workflow (e.g., Claude Code vs. Codex app), ecosystem lock-in, and the subjective “vibe” on your specific game project. In a future post, I will review Claude Code versus the Open AI Codex app ecosystem.
Leave a Reply
Want to join the discussion?Feel free to contribute!